")

Lic. Geol. Francisco Crespo Jimenez
Lic. en geología, Universidad de Granada y Analista en Computación, FAMAF
Estudio Territorial Inmobiliario, Ministerio de Finanzas
Ing. Aldo Algorry
Profesor e investigador de la Universidad Nacional de Córdoba
Responsable de Tecnología y Base de Datos
IDECOR
28 de agosto 2019
Las imágenes a los fines computaciones, son una matriz de puntos (pixeles) de la que es complejo extraer contenidos semánticos. Es decir, responder la pregunta ¿de qué trata esta imagen?
Cada vez más se utilizan técnicas de Inteligencia Artificial, en especial las conocidas como Machine Learning (ML). El Aprendizaje Automático o ML engloba los métodos donde, a través de numerosos ejemplos resueltos, se automatiza el aprendizaje y mejora de manera continua, el desempeño y la calidad de los resultados.
Una estrategia alternativa ofrecen las técnicas de Deep Learning o Aprendizaje Profundo, en particular las denominadas Redes Neuronales Convoluciones (CNN). En Deep Learning los algoritmos de aprendizaje se apilan en una jerarquía de creciente complejidad y abstracción.
Las redes neuronales artificiales son un modelo inspirado en el comportamiento observado de su homólogo biológico: las neuronas cerebrales. Consiste en un conjunto de unidades llamadas neuronas artificiales que se disponen en “capas”, unidas entre sí para transmitir señales en forma de “entradas” y “salidas”. Los datos de entrada atraviesan toda la red neuronal, produciendo ciertos valores de salida.
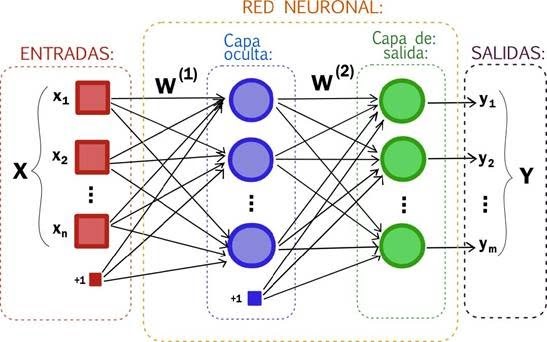
Cada “neurona” está conectada con otras, a través de “enlaces”; en éstos, la salida de la neurona anterior es multiplicada por un “peso”. El producto de la salida de la neurona anterior y los pesos pueden llegar a activar o inhibir las neuronas conectadas siguientes.
La forma de crear una red neuronal responde a un paradigma diferente de la programación tradicional, ya que estos sistemas no son programados de forma explícita, si no que crean modelos a partir de datos de entrenamiento y de “etiquetas” que indican el resultado esperado para cada uno de los datos. De este modo, y a través de procesos de aprendizaje automático, la red va modificando los pesos de las interconexiones para llegar a un estado en el que el error de predicción es mínimo posible.
Las Redes Neuronales Convolucionales (CNN)
El padre de este tipo de modelos es Yann Lecun, con su red llamada LeNet (http://yann.lecun.com/exdb/lenet/). Las CNN posibilitaron un gran salto de calidad en la clasificación de imágenes, pudiendo actualmente alcanzar exactitudes superiores al 90 %.
Las CNN toman una imagen como entrada, la procesan y la clasifican bajo ciertas categorías, como son por ejemplo las “coberturas de suelo”. Estas redes se basan en un proceso denominado “convolución”, que consiste en recorrer una imagen aplicando un filtro y obteniéndose una nueva imagen resultado.
Lo que hace la red neuronal es aprender características de la imagen, que van desde los detalles más pequeños en las primeras capas, hasta una visión más general de la imagen en las últimas. Para detectar las características que forman la imagen y le dan significado, la CNN aprende de una serie de filtros a través de un determinado número de capas mediante convoluciones. Las imágenes obtenidas en la última capa se pasan por un clasificador que nos dirá, con una cierta precisión, a qué clase pertenece la imagen original (por ejemplo, “Cultivo”, ”Bosque”, «Carretera”, etc.).
A – Lo primero es definir la arquitectura de la red, cuántas capas, cuál es la función de costo, etc. La función de costo mide el error que se está cometiendo y lo que se intenta minimizar.
B – Una vez definido nuestro modelo, se comienza a entrenarlo a partir de las imágenes del conjunto de entrenamiento. Cada una de estas imágenes se recorre aplicando filtros, lo que se denomina “convolución”, y otros procesos, obteniendo nuevas imágenes que son tomadas de manera sucesiva capa tras capa.
C – Las imágenes obtenidas en la última capa se pasan a un clasificador (denominado Fully Connected); lo que hace este clasificador es indicar la clase a la que pertenece la imagen original.
D – Como paso siguiente la función de costo evalúa la diferencia entre lo predicho y el valor real. Para mejorar la predicción se ejecuta un procedimiento complejo que incluye recorrer la red en sentido contrario, recalculando los pesos de la red y los filtros, de manera que estos se van ajustando con el fin de minimizar los errores.
E- Se pasa la siguiente imagen de entrenamiento, para que se repitan los pasos B a D y se modifiquen o no los filtros según el error de la función de costo. Y así con todo el conjunto de entrenamiento.
F – El procedimiento de presentar el conjunto de entrenamiento y recalcular la red, se repite hasta alcanzar un error aceptable o hasta que no se pueda bajar más el error.
Después del entrenamiento se aplica el modelo obtenido sobre los datos de validación a fin de conocer cómo se desenvuelve en el mundo real con imágenes que nunca observó o trabajó durante el entrenamiento. Si el modelo obtiene una precisión adecuada trabajando sobre los datos de validación, se habría finalizado el entrenamiento; si la precisión no es la deseada, se deberán modificar algunos “hiperparámetros” de nuestra red y volver a entrenarla.
Los hiperparámetros son como unas “ruedecitas” para hacer un ajuste fino; pueden ser la función de costo, el número de capas de la red, funciones de activación, etc. Son definidos en el punto A y genéricamente se suelen llamar la “arquitectura” de la red. Por último se evalúa la performance final de la red, usando el conjunto de test.
En definitiva, para que una CNN pueda aprender se necesita entrenarla para que calcule los filtros y el clasificador adecuados, y también ajustarla en función de los mejores hiperparámetros. Es un proceso que requiere experiencia y experimentación.
Entre las herramientas más utilizadas para CNN pueden mencionarse librerías como Keras, Pytorch y Tensorflow. Keras es un framework de alto nivel, muy fácil de usar, se puede armar una red neuronal en pocos minutos y con una pequeña cantidad de lineas de código, ya que se usa una programación en bloques. Pytorch y Tensorflow son mas complicados para el desarrollo, ya que son librerías de bajo nivel y se necesita una gran cantidad de código, por su menor abstracción para desarrollar una red neuronal.
Un caso de uso
Un ejemplo de aplicación de estas técnicas podría ser la clasificación de imagen satelitales para la obtención de coberturas de suelo. Puede realizarse un ejercicio utilizando imágenes Sentinel-2, de la Agencia Espacial Europea (ESA), de acceso libre y 10 m de resolución espacial. Como set de entrenamiento para clases de cobertura de suelo, puede utilizarse el conjunto de 27.000 datos etiquetados, desarrollado por la German Research Center for Artificial Intelligence, DFKI GmbH (http://madm.dfki.de/) (Tabla 1).

Tabla 1 – Clases de coberturas de suelo y cantidad de datos para entrenamiento, German Research Center for Artificial Intelligence, DFKI GmbH (http://madm.dfki.de/).
Cada imagen correspondiente al conjunto de datos, forma parte de una clase (etiqueta) y tiene una dimensión de 64×64 pixeles, con un peso de 3 KB. Estas imágenes están compuestas solamente por las bandas del espectro visible de Sentinel (Figura 2). Los datos del set deben separarse en 3 conjuntos: (1) entrenamiento, 75 % – 80 %; (2) validación, 15 % – 10 % y (3) test 10%.

Figura 2 – Ejemplos de clases etiquetadas, set de entrenamiento para coberturas de suelo, German Research Center for Artificial Intelligence, DFKI GmbH (http://madm.dfki.de/).
¿Querés conocer más de lo que se está haciendo en Córdoba con estas nuevas tecnologías? Lee el post Land Cover Córdoba… ¿Qué es el nuevo Mapa de Cobertura de Suelo de la Provincia?


