")

El trabajo con grandes volúmenes de datos geográficos requiere de operaciones espaciales, que actualmente encuentran ciertas limitaciones en los formatos populares de big data, que resultan incompatibles entre sí, lo que dificulta una gestión integral de los mismos.
GeoParquet, el nuevo formato de código abierto para el almacenamiento de datos vectoriales geoespaciales desarrollado por la Open Geospatial Consortium (OGC), se presenta como una herramienta que permite trabajar y estandarizar datos geoespaciales en cualquier sistema que lea o escriba datos espaciales en Parquet.
Si bien su compatibilidad e interoperabilidad para importar y exportar datos geoespaciales, es una de las principales ventajas con las que fue promocionado, probamos este formato y te comentamos otras prestaciones que ubican a GeoParquet a la vanguardia en el procesamiento y almacenamiento de grandes volúmenes de datos geoespaciales.
Parquet y GeoParquet
Parquet (.parquet) es parte del ecosistema Apache Hadoop y tiene las siguientes características:
1. Formato columnar
2. Compresión eficiente
3. Optimizado para lecturas
4. Compatibilidad
5. Esquematización de datos
A diferencia de gran parte de los formatos tradicionales, como CSV o JSON, que lo hacen en filas, Parquet almacena los datos por columnas siendo altamente eficiente, ya que ha sido optimizado para el almacenamiento y análisis de grandes volúmenes de datos en entornos de big data.
GeoParquet es una extensión del formato .parquet, específicamente diseñado para almacenar datos geoespaciales. Se caracteriza por su facilidad de uso y está diseñado para ser interoperable con diversas herramientas y bibliotecas geoespaciales, lo que facilita el intercambio y análisis de datos entre distintos sistemas y plataformas, como Apache Arrow, GDAL y GeoPandas.
Herramientas de gestión de datos interoperables
Estas herramientas facilitan la interoperabilidad de los datos y presentan ciertas características específicas, que detallamos a continuación. Está claro que su uso y mayor aprovechamiento dependerá de los recursos técnicos disponibles y de los conocimientos con los que se cuenta.
Apache Arrow
Es un framework de gestión de datos en memoria que se ha diseñado para optimizar la velocidad y la eficiencia del análisis de datos. Su eficiencia radica en que utiliza un formato de columna que permite un acceso rápido a los datos y una reducción significativa en la cantidad de memoria necesaria para almacenarlos.
Esta particularidad y las que se detallan a continuación, hacen de Arrow una herramienta especialmente útil para el procesamiento y análisis de datos.
- Interoperabilidad: está diseñado para ser un estándar compartido entre diferentes sistemas y lenguajes de programación. Esto significa que puedes mover datos entre diferentes sistemas (por ejemplo, entre Python y Java) sin necesidad de convertir los datos a otro formato, lo que ahorra tiempo y recursos.
- Procesamiento rápido de datos: debido a su diseño eficiente en memoria, permite que las operaciones de análisis de datos sean mucho más rápidas. Esto es particularmente útil para aplicaciones que necesitan procesar grandes volúmenes de datos en tiempo real.
- Compatibilidad con otros proyectos de Apache: Arrow se integra bien con otros proyectos del ecosistema Apache, como Apache Spark, Apache Parquet, y Apache Drill, lo que facilita su adopción en entornos de big data.
- Ecosistema en crecimiento: además de la interoperabilidad con lenguajes de programación populares como Python, R, Java y C++, Apache Arrow es compatible con una variedad de bibliotecas y frameworks de ciencia y análisis de datos, lo que lo convierte en una herramienta muy versátil para desarrolladores y científicos del sector.
Geospatial Data Abstraction Library (GDAL)
La Geospatial Data Abstraction Library (GDAL) es una biblioteca de código abierto para la manipulación y conversión de formatos de datos geoespaciales. Ofrece una amplia gama de funcionalidades para trabajar con datos raster y vectoriales.
GDAL presenta las siguientes particularidades:
- Manipulación de datos geoespaciales: permite leer, escribir y transformar datos geoespaciales en una variedad de formatos. Esto incluye datos raster (como imágenes satelitales) y datos vectoriales (como shapefiles).
- Compatibilidad con múltiples formatos: soporta una amplia gama de formatos de datos geoespaciales, incluyendo GeoTIFF, Shapefile, KML, GeoJSON, y muchos más. Esto lo hace extremadamente útil para la interoperabilidad entre diferentes sistemas y aplicaciones.
- Procesamiento de datos: incluye herramientas para la reproyección de datos, recorte, mosaico, y muchas otras operaciones geoespaciales. Esto es especialmente útil para la preparación y limpieza de datos antes de su análisis.
Con las últimas versiones de GDAL, es posible leer y escribir archivos GeoParquet directamente. Esto permite a los usuarios aprovechar las ventajas del formato Parquet para datos geoespaciales dentro de su ecosistema de herramientas.
GDAL también puede ser utilizada para transformar y procesar datos geoespaciales almacenados en GeoParquet. Por ejemplo, es posible utilizarlo para re proyectar datos de un sistema de coordenadas a otro, recortar datos a una región de interés específica, o realizar operaciones de geometría avanzada.
Utilizar GDAL con GeoParquet, también permite integrar datos geoespaciales en flujos de trabajo de big data y análisis, y aprovechar otras herramientas compatibles con Parquet, como Apache Arrow, Apache Spark y muchas más.
DuckDB
Es una base de datos analítica en memoria que ha ganado popularidad por su rendimiento y simplicidad, especialmente en el análisis de datos. Tiene soporte nativo para leer y escribir archivos Parquet, incluyendo GeoParquet, lo que permite realizar operaciones geoespaciales directamente en su entorno.
DuckDB puede ser una opción muy eficiente para realizar análisis geoespaciales, ya que combina la simplicidad de una base de datos SQL con la capacidad de manejar datos en formato Parquet. A diferencia de las funciones geoespaciales de POSTGIS, DuckDB no cuenta con la cantidad de estas características, pero permite realizar las tareas más comunes y necesarias.
Gestión de datos de la IDE con GeoParquet
En IDECOR comenzamos a realizar tareas específicas de procesamiento de datos con la herramienta de DuckDB en el formato .parquet, lo que posibilita trabajar en distintos entornos y centralizar las tareas analíticas.
Desde las primeras pruebas de análisis geoespacial realizadas en distintos entornos, pudimos comprobar sus ventajas relacionadas a portabilidad, velocidad y operabilidad de los archivos .parquet.
- Portabilidad: el tamaño de los archivos se reduce entre un 40 a 60 por ciento. Por ejemplo, archivos de 140 MB en formato geopackage se reducen a 50 MB, o tablas que en Postgres sin índices ocupan alrededor de 200 MB llegan a reducirse a 70 MB.
- Velocidad de procesamiento: es otra gran característica, incluso en procesamientos geoespaciales como intersecciones de grandes cantidades de registros, donde por ejemplo, un procesamiento de cuatro horas con otro entorno similar, se llega a procesar en menos de una hora en este formato.
- Operabilidad: si bien nos centramos en usar el procesamiento en el entorno de DuckDB, realizamos pruebas de fiabilidad de los datos con desarrollos ya probados, sobre la estructura de base de datos de POSTGRES/POSTGIS, con entornos de Python y frameworks de análisis, como Pandas o GeoPandas.
Algunos ejemplos de uso
Como primera medida utilizamos las capas de parcelas urbanas del Catastro Provincial, disponibles en las Descargas de Mapas Córdoba. Con comandos del entorno de GDAL, convertimos dichas capas a formato de GeoParquet:

El resultado es una capa en GeoParquet con un peso de 40 MB, fácilmente transportable y usable en cualquier entorno que posea los recursos para realizar tareas analíticas.

Como se puede ver en la imagen, el archivo se puede visualizar y utilizar en software especializados en GIS.
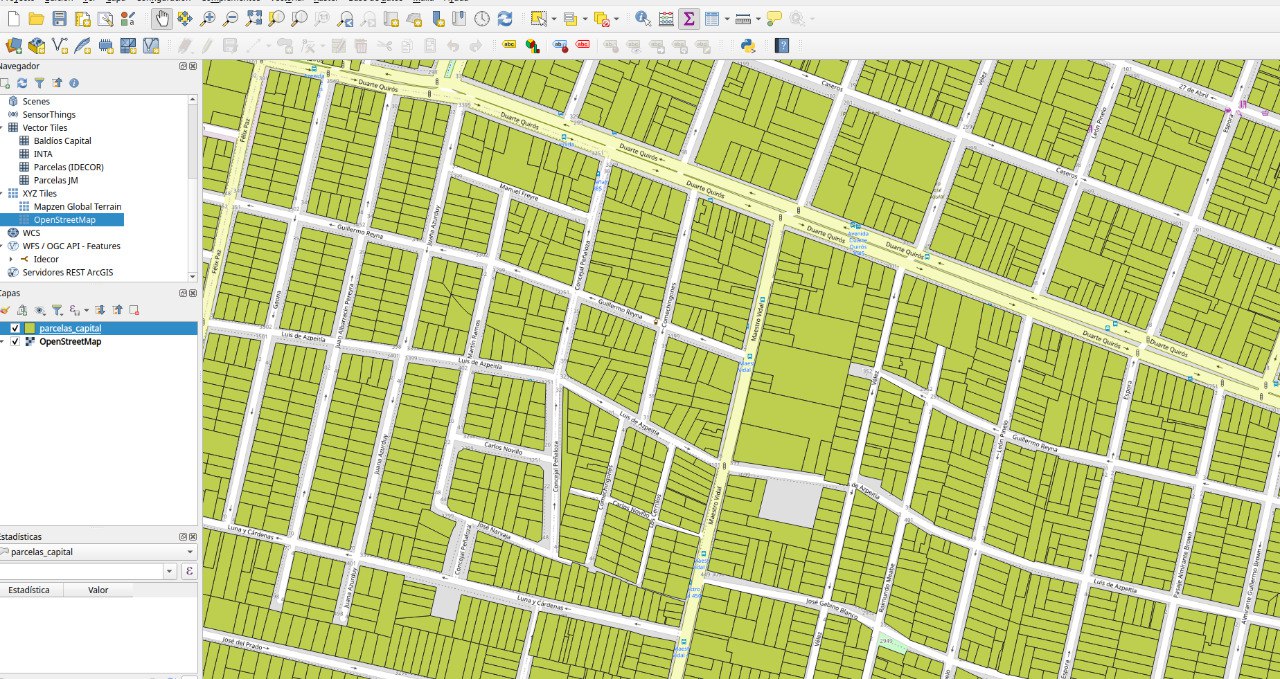
En otro ejemplo, utilizamos una intersección de una capa de 170 mil (parcelas rurales) registros con una capa de variables con 700 mil registros (grilla de variables), el resultado es archivo con alrededor de 1.400.000 registros, que luego son usados para establecer el valor de las parcelas rurales.
Este proceso en un entorno de una base de datos, puede requerir cerca de 2 horas, con las librerías de DuckDB y el soporte de los archivos GeoParquet se realiza en menos de una hora.

Los resultados fueron más que satisfactorios y, como se puede observar en el código del ejemplo, realizamos tareas en Python con la librería de DuckDB.
De esta forma probamos la interoperabilidad, la usabilidad, la adaptabilidad y la fiabilidad del formato de almacenamiento de Parquet.
Si te interesa este tipo de contenidos podés sumarte a IDECOR-Dev, la comunidad de desarrollo de aplicaciones y geoservicios de la IDE provincial.
Por consultas o para conocer más sobre estos recursos, escribinos a [email protected]. Informate sobre las ‘Novedades IDECOR’, en nuestras redes Instagram y en Linkedin.
Colaboración:
IT. Carlos Salinas,
Anal. de Sist. José Jachuf,
Est. Nicolás Benjamín Oller,
IDECOR


