")

Contribución:
Juan Pablo Carranza
Mgter. en Admin. Pública y Lic. en Economía, U.N.C.
Estudio Territorial Inmobiliario, Ministerio de Finanzas
19 de junio 2019
Algo muy simple e inmediato para el ojo humano, como mirar una imagen satelital y distinguir entre una construcción y un espacio verde, toma trabajo y requiere de un proceso de aprendizaje para una computadora. Sin embargo, una vez que dicho proceso de aprendizaje concluye y la computadora está en condiciones de enfrentarse a una imagen satelital y discernir por sus propios medios entre píxeles de una categoría y otra, puede efectuar en una fracción de segundo múltiples cálculos que son imposibles de realizar “a simple vista” por un ser humano.
Si bien existen muchas opciones gratuitas o semi-gratuitas que son utilizadas para realizar procesamiento de imágenes satelitales (Google Earth Engine, The Sentinel Toolbox, ORFEO Toolbox, SOPI de CONAE, entre otras), es escasa la difusión y utilización de R en este tipo de estudios, a pesar de ser uno de los softwares de código abierto más usados actualmente en el ámbito de la ciencia de datos.
El objetivo del presente escrito es explorar el potencial de R como herramienta flexible, gratuita y de calidad que podría aplicarse o enriquecer el procesamiento de imágenes satelitales, al tiempo que brindar unas pocas líneas de código para reproducir una clasificación real.
Ejemplo de aplicación y área de estudio
Se llevará adelante un ejemplo de clasificación de pixeles en construido y no construido en un sector de la zona norte de la Ciudad de Córdoba, próxima al Aeropuerto Internacional Ambrosio Taravella. Se trata de un espacio complejo, en donde la trama urbana comienza a perder densidad de ocupación y se entremezclan áreas de tierra vacante con barrios cerrados, asentamientos informales y zonas industriales (Imagen 1).
Se trabajará con una imagen Sentinel 2, descargada de Sentinel Hub en falso color urbano, que implica la utilización de 3 bandas de un total de 12 disponibles; se utilizarán las bandas 12 (SWIR – infrarrojo de onda corta), 11 (también SWIR, pero en una longitud de onda diferente) y 4 (rojo). Las bandas 11 y 12 tienen una resolución espacial de 20 metros, mientras que en la banda 4 la resolución aumenta a 10 metros (para acceder a la imagen utilizada haga click aquí)
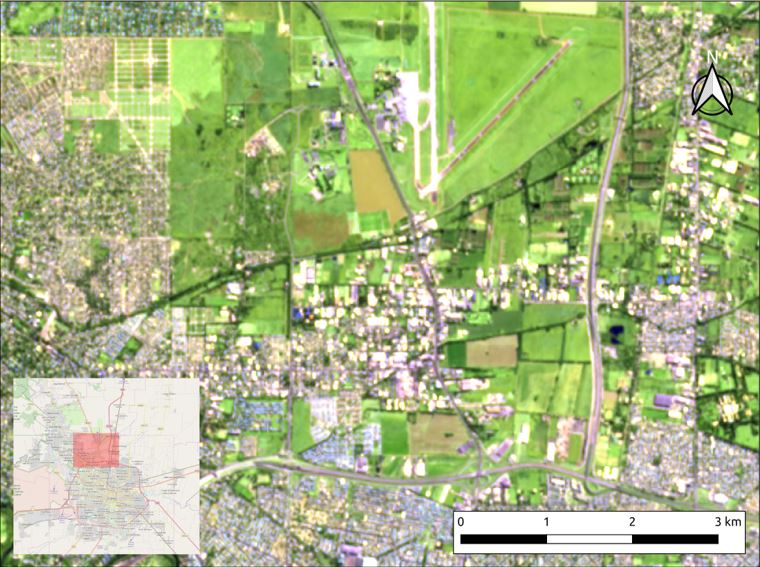
Fuente: Elaboración propia en base a imágenes satelitales Sentinel 2.
El proceso de muestreo
En esta instancia se seleccionan muestras de cada una de las características territoriales para las cuales se desea entrenar el algoritmo, con el objetivo de que “aprenda” a distinguirlas automáticamente.
El proceso de muestreo es crítico para asegurar buenos resultados. Si en el universo a estimar existen características que no han sido muestreadas de manera adecuada, los resultados serán deficientes. Esto es así ya que el algoritmo “aprende” de la información provista en la muestra y luego predice en función del aprendizaje logrado. Dado que en esta oportunidad nos interesa explorar e introducir la potencialidad del software R en el procesamiento de imágenes, el muestreo realizado fue algo rudimentario y acotado. Se seleccionaron 11 polígonos correspondientes a áreas claramente edificadas, 5 polígonos que se corresponden con áreas cubiertas de vegetación y 6 polígonos con agua. Algunas de las muestras utilizadas pueden apreciarse en la imagen 2 (puede descargarse el archivo de muestras haciendo click aquí).
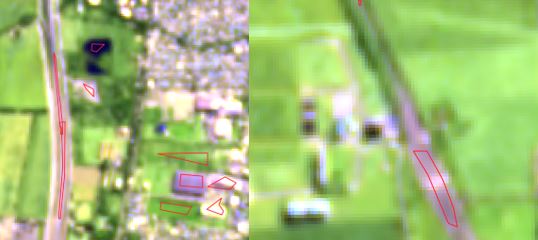
Fuente: Elaboración propia en base a imágenes satelitales Sentinel 2.
El entrenamiento del algoritmo
Una vez definidas las muestras a utilizar, que se corresponden con polígonos (datos vectoriales), se superponen con la imagen clasificar; de esta forma, se contará con información sobre la composición de los píxeles dentro de cada uno de los polígonos muestreados, fundamental para el análisis a realizar. Dentro de cada polígono de la muestras existen muchos píxeles, lo que genera que el tamaño de la misma termine siendo mucho mayor. En este caso, se pasa de un total de 22 polígonos muestreados a un conjunto de 33.589 píxeles de entrenamiento.
Con la muestra de píxeles (en lugar de polígonos) se procede al entrenamiento de un algoritmo llamado Random Forest (Breiman, 2001), que es una generalización de un árbol de regresión y clasificación (Breiman, et. al, 1984). La lógica del algoritmo descansa en la realización de múltiples árboles de clasificación, en donde cada uno de ellos tiene la misión de subdividir recursivamente la muestra en dos subconjuntos, en función de una variable de respuesta (en este caso, la condición de “construido” y “no construido”). El objetivo del algoritmo es, entonces, lograr dos subconjuntos que maximicen la diferencia entre ellos y a la vez, minimicen la diferencia dentro de los elementos que los integran.
Para obtener múltiples árboles utilizando el mismo conjunto de datos, se aplica un procedimiento conocido como “bootstrap aggregating”, o más comúnmente “bagging”, que consiste en un remuestreo con reemplazo en los datos de entrenamiento. Además, se impone la selección aleatoria de variables independientes a considerar en cada partición. Estas dos restricciones permiten construir múltiples árboles de clasificación a partir del mismo conjunto de datos muestrales, lo que reduce la correlación entre árboles y posibilita el trade-off entre sesgo y varianza, elevando notablemente la capacidad predictiva del algoritmo cuando se enfrenta a datos que no han sido debidamente muestreados.
La principal ventaja de R en el procesamiento de imágenes radica en su flexibilidad, dada la gran cantidad de algoritmos que pueden aplicarse y la estructura de código abierto que permite al investigador escoger el mejor diseño metodológico. La librería “caret” resume una gran cantidad de algoritmos, que pueden consultarse haciendo click aquí. Sin embargo, si la muestra es buena, los resultados de distintos algoritmos no deberían ser muy diferentes.
Resultados obtenidos
La clasificación de cada uno de los árboles para cada uno de los píxeles cuya clase se desea estimar, se somete a una “votación”, resultando escogida aquella categoría que surja del voto mayoritario.
El resultado de este proceso se puede apreciar en la Imagen 3, que muestra en color rojo la estimación de píxeles construidos sobre la imagen satelital estudiada. En el recorte aplicado en la Imagen 3 se detectaron 19 km2 de áreas construidas y 39 km2 de espacios abiertos; es decir, un 32,75% del espacio se encuentra construido.
El proceso de entrenamiento del algoritmo (Random Forest) tuvo una exactitud (accuracy), medida a partir de un proceso de validación cruzada, de 99,34% y un coeficiente Kappa de Cohen igual a 98,20%.
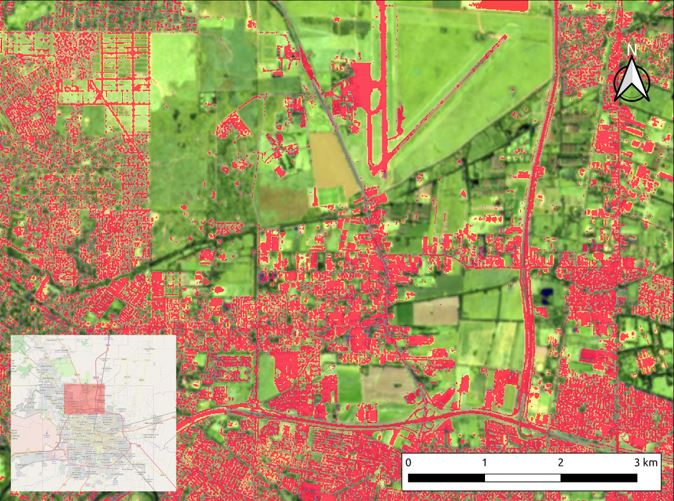
Fuente: Elaboración propia en base a imágenes satelitales Sentinel 2.
Aprovecha el código!
Para continuar explorando, aprender o incluso mejorar este primer ejercicio, puedes descargar el código completo.
Muestra de una parte del código en R:
# Función que superpone las muestras encima de la
imagen satelital.
for (i in 1:length(unique(muestras[[responseCol]]))){
category <- unique(muestras[[responseCol]])[i]
categorymap <- muestras[muestras[[responseCol]] == category,]
dataSet <- extract(img, categorymap)
dataSet <- dataSet[!unlist(lapply(dataSet, is.null))]
if(is(muestras, “SpatialPointsDataFrame”)){
dataSet <- cbind(dataSet, class = as.numeric(category))
pixeles <- rbind(pixeles, dataSet)
}
if(is(muestras, “SpatialPolygonsDataFrame”)){
dataSet <- lapply(dataSet, function(x){cbind(x, class =
as.numeric(rep(category, nrow(x))))})
df <- do.call(“rbind”, dataSet)
pixeles <- rbind(pixeles, df)
}
}
Nota: para instalar R hacer click aquí; se recomienda instalar el IDE “R-Studio” haciendo click aquí.
Bibliografía consultada:
- Breiman L., Friedman J., Stone C., Olshen R. (1984): “Classification and Regression Trees”. Ed. Taylor & Francis.
- Breiman L. (2011): “Random Forests”. Machine Learning, 45, pp. 5–32. Disponible en: https://link.springer.com/content/pdf/10.1023/A:1010933404324.pdf
- Hastie T., Tibshirani R., Friedman J. (2001): “The elements of Statistical Learning”. Ed. Stanford University. Disponible en: https://web.stanford.edu/~hastie/Papers/ESLII.pdf


