")

Contribución;
Mg. Federico Monzani y Mg. Juan Pablo Carranza, IDECOR
Dr. Mariano Córdoba, CONICET – IDECOR
29 de abril 2020
Los estudios geográficos de diversas problemáticas requieren con frecuencia la definición de zonas homogéneas o áreas de estudio que permitan segmentar los análisis. Dentro de cada una de éstas, los elementos que las integran comparten determinadas características que los hacen esencialmente diferentes de los elementos de las otras zonas o áreas.
Existen diversas estrategias metodológicas para el diseño de zonas o áreas geográficas, desde la opinión de expertos basada características físicas del terreno o usos y costumbres, hasta técnicas matemáticas multivariadas que buscan potenciar la objetividad en su delimitación. Cada uno de estos enfoques tiene ventajas en el estudio de una problemática dada, como también puntos débiles, que son necesarios tener en cuenta a la hora de emprender el análisis y tomar las decisiones en su desarrollo.
El presente artículo presenta la aplicación de diversas técnicas estadísticas y herramientas de software a partir de un caso de construcción de zonas económicas ad-hoc, realizadas por IDECOR en el marco del estudio del valor de la tierra rural en la Provincia de Córdoba.
¿Con qué propósito se zonifica?
El desarrollo de la ciencia de la computación, junto con el avance de software estadísticos, la explosiva disponibilidad de datos georreferenciados y el avance de las IDE (Infraestructura de Datos Espaciales) están posibilitado ejecutar análisis geoespaciales cada vez más sofisticados, facilitando el uso de las técnicas computacionalmente intensivas en la zonificación del espacio geográfico.
El análisis de clústeres (o conglomerados) tiene por objeto agrupar un conjunto de observaciones de tal manera que los objetos u observaciones que pertenecen al mismo grupo (cluster o conglomerado) sean más similares entre sí respecto a observaciones que pertenecen a otros clusters. Esta metodología es de uso frecuente en minería de datos y para el análisis estadístico, siendo utilizada en muchos campos de aplicación, incluido aquellos referidos a estudios de fenómenos territoriales.
Desde el punto de vista metodológico, diversos tipos de algoritmos de clusterización pueden ser implementados. Uno de los más difundidos es el denominado Fuzzy c-Means Clustering, en conjunto con el de Análisis de Componentes Principales (ACP), que permite identificar las variables que reseñan las zonas establecidas.
Para aprender basados en un ejemplo analizaremos la “Zonificación Agroeconómica del Sector Rural de la Provincia de Córdoba”, realizada en el marco de los estudios inmobiliarios de la provincia de Córdoba, trabajo presentado por el equipo de IDECOR en las 50° Reunión Anual de la Asociación Argentina de Economía Agraria (AAEA).
El estudio fijó el objetivo de definir 5 zonas agroeconómicas en la provincia, relacionadas con variables agrícolas, ganaderas y factores del Producto Geográfico Bruto (PGB). Las variables utilizadas en la zonificación fueron construidas con información disponible en MapasCordoba, el portal de la Bolsa de Cereales de la Provincia Córdoba, la Dirección General de Estadística y Censos de la Provincia, el Ministerio de Agricultura, Ganadería y Pesca de la Nación, y el Ministerio de Agricultura y Ganadería de Córdoba.
El algoritmo Fuzzy c-Means
En una primera instancia se identificaron zonas agroeconómicas usando el método Fuzzy c-Means. Este algoritmo de clusterización no jerárquica, consiste en una descomposición o partición única de los datos en un número determinado de grupos, que debe ser definido a priori por el investigador. Para ello, pueden calcularse índices (coeficiente de partición, entropía de partición, entre otros) que permiten definir el número de grupos o zonas óptimo. El conocimiento del investigador es otro criterio muy utilizado para definir el número de zonas que mejor representa la estructura de los datos.
Definidas las particiones, se aplica el algoritmo Fuzzy c-Means, que consiste en minimizar una función de distancia (euclidiana, Mahalanobis, Manhattan, entre otras), que relaciona un punto u observación con el centroide o centro del grupo establecido previamente en el hiperplano. El método refiere a una partición difusa, “suave”, en la que se define el grado de pertenencia de cada observación a cada uno de los clusters. Finalmente, se define la ubicación de cada observación al grupo en el cual presente el mayor grado o probabilidad de pertenencia.
En el análisis realizado se utilizaron más de 30 variables agropecuarias, geográficas y vinculadas al PBG (Figura 1). El resultado de las 5 zonas se presenta en un mapa a nivel departamental (Figura 2).
Análisis de Componentes Principales (ACP)
En una segunda instancia y por medio del ACP, se procuran caracterizar las zonas definidas por el algoritmo Fuzzy c-Means. La misma consiste en reducir el número total de variables observadas en un conjunto de “variables sintéticas”, linealmente independientes, que capturen la mayor información del objeto bajo estudio. Estas variables se denominan Componentes Principales (CP) y surgen al realizar una transformación ortogonal de las variables originales. Las CP se pueden entender como variables índices que sintetizan las variables originales.
La transformación ortogonal conlleva a preservar la isometría euclidiana entre los elementos del objeto de estudio (individuos y variables), conservando los ángulos y distancias entre los mismos.
Del análisis surgen los “valores propios”, que reflejan la “varianza” explicada por cada CP y los “vectores propios”, que permiten cuantificar la contribución de cada variable original en la conformación de aquellas.
Finalmente, además de capturar la mayor información posible de las variables germinales, el ACP reduce el problema al plano bidimensional, donde las coordenadas son las CP. Y permitiendo trabajar en el espacio de las variables o de las observaciones donde se mantiene la isometría euclidiana.
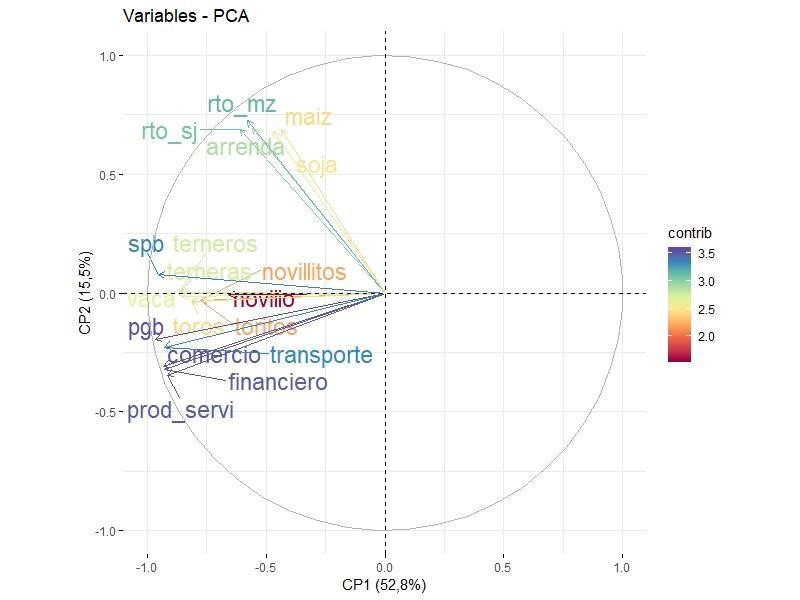
El Grafico 1 refleja el plano de las variables, donde la Componente Principal 1 evidencia el 52,8% de la variabilidad y está integrada mayormente por variables relacionadas por el Producto Geográfico Bruto, tales como servicios financieros, servicios de transporte, producción de servicios y valor agregado del comercio. La Componente Principal 2, en tanto, revela el 15,5% de la variabilidad y está conformada por las variables relacionadas con el sector agropecuario, tales como rendimiento de soja, maíz en qq/ha o valor del arredramiento rural en qq/ha.
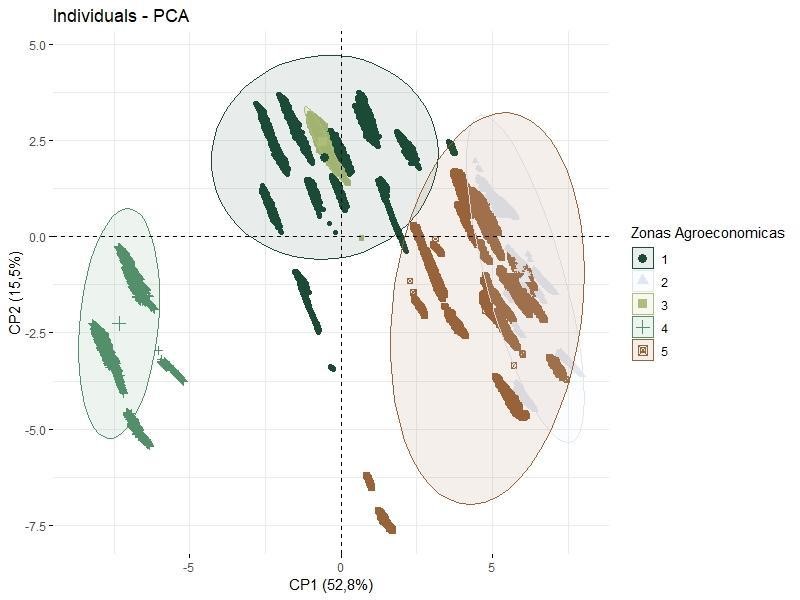
El Grafico 2, en cambio, se expresa en el plano de las observaciones (individuos), en el cual están representadas las 5 zonas definidas por el algoritmo Fuzzy c-Menas. Las zonas 1 y 3 se caracterizan por estar relacionadas con la Componente Principal 2, conformada mayoritariamente por variables agropecuarias; mientras que las zona 4, 5 y 2 se ven caracterizadas por la Componente Principal 1, conformada por las variables derivadas del PGB. La zona 4 lo hace en forma positiva con las variables relacionadas al PGB, tales como servicios financieros, de transporte y comercio; y las zonas 5 y 2, en cambio, se relacionan en forma negativa con estas variables.
A fines didácticos se expresó el plano de las variables y el plano de los individuos en forma separada (dos gráficos). Sin embargo, como ambos planos están reflejados dentro de las mismas componentes principales, podría graficarse un Bi – plot, que une el plano de las variables y de los individuos en un mismo gráfico.
En conclusión, en función de los resultados obtenidos, es posible caracterizar a las zonas de la siguiente manera:
Zona 1 – Zona predominantemente agrícola de la provincia de Córdoba, dado que en su conformación influye de manera preponderante la Componente Principal 2, conformada por las variables de naturaleza agropecuaria.
Zona 2 – Arco noroeste de la provincia de Córdoba, caracterizada por ser una zona con retrasos en el desarrollo socio-económico, de escasos recursos naturales (en términos relativos a otras zonas de la provincia) y baja participación en el PGB.
Zona 3 – Identificada como una zona preponderantemente ganadera, dada la conformación de la Componente Principal asociada.
Zona 4 – Sector de alta densidad poblacional, donde se encuentran las ciudades de San Francisco y Río Cuarto; se califica por una elevada participación en el PGB.
Zona 5 – Sector de transición, donde se observan determinadas características comunes con la Zona 2, en conjunto con actividades propias del turismo, que elevan la participación en el PGB.
¿Necesitás desarrollar zonificaciones geográficas?
La metodología desarrollada puede ser aplicada a distintos fenómenos territoriales que en su análisis requieran de la zonificación del espacio. Si requieres profundizar, puedes acceder al artículo completo en el siguiente link o contactar con el equipo de Modelización y Métodos de IDECOR en [email protected].


