")

La sinergia entre inteligencia artificial (IA) e infraestructura de datos espaciales (IDE) es una oportunidad y a la vez un desafío, dada la inmensa cantidad de datos que se están generando e integrando en el marco de las IDE, lo que podemos identificar como “big (geo)data”.
Ante el creciente uso de dispositivos tecnológicos e interconectados, se producen constantemente gran cantidad de datos de diversas temáticas y localización. Subir una foto a alguna red social o compartir la ubicación en aplicaciones de mensajería instantánea, son formas de producir datos actualizados, pero más importante aún, georreferenciados. Frente al volumen creciente de este tipo de datos, desde las iniciativas IDE debe comenzar a prestarse atención al análisis y procesamiento de los mismos, brindando adecuada orientación y soporte a productores y usuarios.
En 1950 el matemático Alan Turing, quien sería el pionero de la inteligencia artificial, se preguntaba si las maquinas podían pensar. Desde entonces se avanzó en forma acelerada en la investigación y desarrollo de esta área computacional. Hablar de inteligencia artificial hace referencia al uso de técnicas inteligentes para el análisis de datos. A través de algoritmos que ajustan determinados parámetros, a medida que se incorporan nuevos datos, “aprenden” el comportamiento de aquellos, entre sí y respecto de determinados fenómenos.
Así, surgen nuevas oportunidades para investigar múltiples problemáticas atravesadas por la dinámica territorial, como la concentración geográfica de la pobreza y riqueza, patrones de ocupación del suelo, crecimiento urbano, valor de la tierra, entre muchos otros. Una dificultad ante el potencial de la IA es el acceso a grandes volúmenes de datos. Las IDE pueden ser una respuesta valiosa en este sentido. Sus políticas de datos abiertos, documentación e interoperabilidad de diversas fuentes y temáticas, permiten disponer de datos estructurados para la aplicación de algoritmos de inteligencia artificial.
IDECOR cuenta con una gran cantidad de mapas y datos específicos desarrollados en el marco del Estudio Territorial Inmobiliario, que se publicarán hacia fin de año y estarán disponibles para uso en línea o descarga. Un área interesante podría ser el sector agropecuario, buscando conocer por ejemplo: rindes por hectárea de un determinado cultivo, con un grado de detalle mayor que las estadísticas departamentales… es posible hacerlo a partir de distintas variables -en forma objetiva- y a nivel de pequeñas unidades cartográficas.
Teniendo en cuenta datos climáticos (temperaturas, radiación solar, etc.), edafológicos (suelos, pH, materia orgánica, nitrógeno, potasio, etc.), cobertura del suelo (land cover) y topográficos (altura y pendiente, a partir del modelo digital de elevaciones de la provincia), entre otros, es posible construir una estimación robusta. Utilizando un algoritmo como Random Forest, que establece y aprende en base a la interacción de todas las variables que a priori tienen relación con el rendimiento de dicho cultivo, puede generarse una estimación sólida.
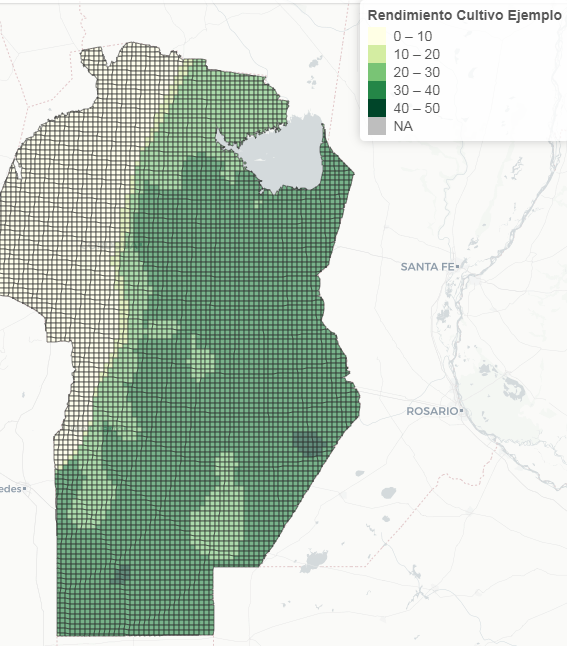
Lo valioso de estos modelos, además, es que “aprenden” el comportamiento de las variables y con el paso del tiempo, dada la relativa facilidad de aplicación e incorporación de nuevos datos, las estimaciones serán cada vez más robustas.
El alcance de esta herramienta en el área geoespacial traerá consigo un desarrollo importante, brindando información cada vez más útil al alcance de los usuarios y actores de la IDE. Y así, de las políticas públicas y el desarrollo.
Contribución de: Micael Salomón, Licenciado en Economía, U.N.C. Estudio Territorial Inmobiliario, Ministerio de Finanzas


